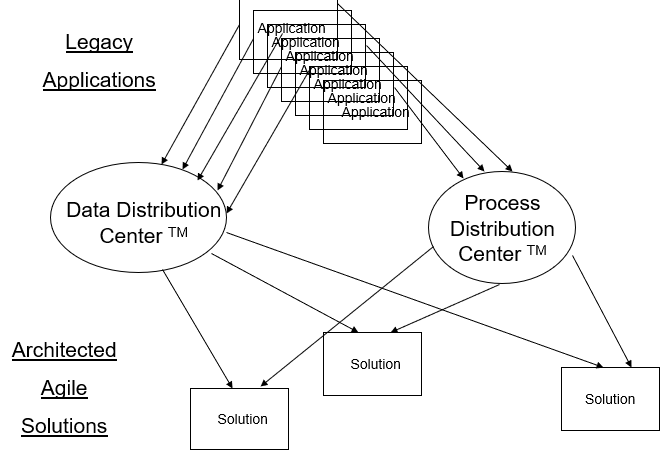
A foundational step is the creation of a Data Distribution Center - a centralized, ontologically structured data hub that ensures organization-wide consistency, traceability, and governance of enterprise data. Like a modern-day Dewey Decimal System, this structure classifies and aligns data to business needs, ensuring quality inputs for AI processing engines. Coupled with continuous, closed-loop improvement, EAI helps organizations move away from open-loop risks, compounding quality over time for increasingly better outcomes.
Ethical and Strategic Wins
The ethical dimension is inescapable. As data regulations tighten and public scrutiny intensifies, organizations deploying AI must be able to prove the source, ownership, and consent behind their data. EAI’s focus on closed, proprietary, and authentically obtained information not only avoids the landmines of copyright and privacy violation, it also delivers practical benefits - lower costs, reduced risks, and a measurable edge over competitors still reliant on public or questionable datasets.
Conclusion: From Fool’s Gold to Sustainable Value
The promise of AI cannot be separated from the quality of its fuel. Sophisticated algorithms built on sand will yield only digital fool’s gold - shiny, but lacking substance. For the agile enterprise, the future lies in harnessing the data they already own, architected for visibility, traceability, and strategic impact. By placing enterprise data - the organizational DNA - at the heart of their AI strategy, businesses transform technology into true, defensible advantage.
Gaining Competitive AI Advantage with Enterprise Architecture